Generally, answers to questions of the numerical capture, analysis or representation of mass phenomenons like allele frequencies in populations are given by statistics and probability calculus. Readings of experiments may be grouped around a mean (= mean value). To find out whether two series of readings represent basically the same or significantly different values, the t-test is performed. It answers the question of how far the means of the two readings differ from each other.
The chi2-test is done to see if a result corresponds with the theoretically expected values. The smaller the chi2-value the more probable it is that a deviation is caused merely by chance.
MENDEL, his rediscoverers and the geneticists of this century never got exact but only approximate ratios in their crossings. Ratios like 3:1 or 1:1 are idealized values. Though the interpretation of the mechanism they are based on is plausible, several questions have to be asked not only by a mathematician but also by a practical geneticist:
![]() How large is the deviation from the theoretically expected
values allowed to be?
How large is the deviation from the theoretically expected
values allowed to be?
![]() How many specimens have to be counted to regard the results
as reliable?
How many specimens have to be counted to regard the results
as reliable?
![]() Is there a way to reach the same results with less
bother?
Is there a way to reach the same results with less
bother?
Answers to these questions are given by statistics or probability calculus. Therefore, a clear yes or no is never to be expected, instead, the answers will be with how many percent probability an event corresponds with an assumption or whether there is a significant difference between two series of readings. The geneticist is helped by several formulas that he can use for his values and by calculated standards documented in tables that he can refer to. The decisive precondition for the use of the mathematical approaches is the choice of the right formula. It has to be clear whether the own, experimentally gained data satisfy the respective conditions. They all have to share the same dimensions, absolute values cannot be mixed up with relative values (in percent). Further preconditions that have to be taken into account when performing the respective statistic tests can be found in reviews like that of ZAR (1984).
The mean of a series of values
is calculated as follows:
X = sum xi / n
where xi represents the single values and n the number
of the values.
Mean variation (=
variance):When depicting the readings in a histogram, it
is usually easily discernible whether they are grouped around a mean
or not. If the readings stem from a Gaussian
normal distribution, the resulting curve will be
bell-shaped with an increasing number n. Only if this is the case, it
makes sense to go on working with it statistically as is shown in the
following.
The picture (below) shows that the curve of a Gaussian normal
distribution can be described by the position of its maximum that
corresponds to its mean X and its points of inflection. The distance
between X and one of the points of inflection is called mean
variation or standard deviation.
The square of the mean variation is the variance. A series of
readings is always a more or less large spot check of a totality.
Spot checks do always have a relative error, the
standard error or standard
deviation of the mean, whose size is dependent on the number of
readings. It can mathematically be expressed by 1 / square
root n.
The readings have at first to be standardized, the type and the degree of divergence of a Gaussian normal distribution have to be taken into account. The mean variation of a spot check (s = square root of the medium quadratic deviation) can be ascertained by the following formula:
s = square root [xi - X]2 / n - 1
By integration of the Gaussian normal distribution, the area
marked by the base line and the curve area from + 1
sigma, 2 sigma, 3 sigma etc. can be
calculated:
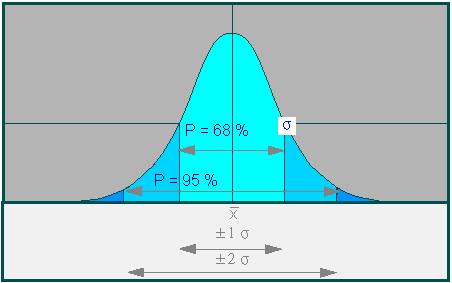
Parameter of a Gaussian distribution: The value P refers to the part of the area that is enclosed by the curve and the base line between the values + and -1 sigma, (light blue area) and + and -2 sigma (light blue + medium blue area), respectively, or + and -3 sigma (light blue + medium blue + dark blue areas).
This means that 68.3 percent of all readings of an ideal distribution scatter with 1 sigma, 95.4 percent with 2 sigma and 99.7 percent with 3 sigma around the mean. These values are important since they are used as standards for most statistical statements. It is thus important for a practitioner to measure and to incorporate his own readings critically so that they can refer to such an ideal distribution.
An ever repeating question is whether two (or more) series of
readings represent significantly different results or whether
different means are caused merely by chance and have thus different
values as a result of 'errors'. To solve the problem, the relation of
the means of both series to the standard deviation have to be
compared. For the comparison of two series of readings, the t-test is
used. The aim of the comparison is the examination, how far the means
Xa and Xb differ from each other. The measure
for this is the quantity t.
The probability P that corresponds to a calculated t can be found in probability tables. If Xa and Xb vary more than Xa + 3 sigma, it is spoken of a significant difference. The probability that both values tally is < 0.3% meaning that the probability that both represent distributions different from each other is > 99.7%. If the difference is larger than Xa + 2 sigma but smaller than Xa + 3 sigma, then it is spoken of a secure difference. In this case, the probability (P) of the correspondence is about five percent, the probability of difference is accordingly 95 percent. 3 sigma and 2 sigma respectively are also referred to as a one percent and a five percent respectively degree of confidence. It is common to use fractions of the number 1 instead of percent in statistics, P would thus be 0.01 and 0.05 respectively. Two further things become clear when looking at the table:
In a prevoiusly shown table, the splitting ratios obtained by MENDEL have been depicted. He extrapolated a 3:1 ratio. The chi2-test shows whether this is permitted:
d = divergence of the expected result, e = expectation. The smaller the value of chi2, the more probable it is that only chance is responsible for a divergence. Only absolute numbers (never percentages) can be used for the chi2-test. The test shows that the correspondence of MENDEL's numbers with his expectations is very high. The mathematically calculated values for the expectations can also be found in the respective tables. Later studies showed that even much smaller amounts of data are sufficient to obtain significant values.
|
|