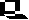
The features distinguishing a living system – at least a living system on earth, conditions and consequently also living systems may be different if existing in other parts of the universe – from all other systems are:
Each of these features characterizes one or the other of the discussed molecular classes, but none of the molecules alone meets all the requirements.
It is well-known that all cells contain both nucleic acids and proteins, and it is moreover known, that the molecules of both classes interact. This brings us a decisive step further towards the answer to the question what life is. Life can be regarded as a feature of a system the elements of which are molecules belonging to different classes.
Are proteins and nucleic acids the only types of molecules belonging to this system? The genetic information serves to produce polypeptide chains, i.e. proteins. The value of the information contained in the nucleic acids is to make sure that certain proteins can be produced. Information about proteins helping in the replication of nucleic acids and thus enabling a transmission of information mostly free of mistakes is primarily especially useful. A system of nucleic acids and proteins helping to replicate them makes up an important basis for evolution, because evolution can only be considered if an obtained state of information can be maintained and extended. These facts can be depicted as a hypercycle.
The dependencies can be illustrated by the formation of a hypercycle.
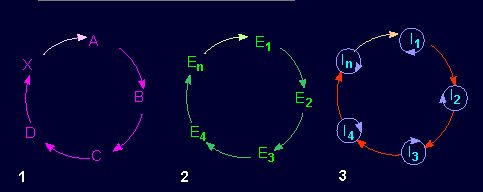
Hierarchy of cyclic reaction networks. 1. Catalysts (enzymes, E) catalyze subsequent reactions. The citric acid cycle is an example of this type. 2. Autocatalysis (units replicating themselves). Enzyme one catalyzes the production of enzyme two that again catalyzes the production of enzyme three and so on, while enzyme n (En) does finally catalyze the production of enzyme one (E1), so that the circle is closed. 3. A catalytic hypercycle. One autocatalytic process instructs the course of the next. The total course is again an autocatalytic cycle (according to M. EIGEN and P. SCHUSTER, 1977).
These equations are described by linked non-linear reactions. Or, in other words, it is a result of reactions of second order. A hypercycle differs fundamentally from cyclic processes. Strictly speaking, it describes a chain of reactions that have to be depicted as a screw, since it does symbolize both a growth function and a control circuit with feedback. Both features are causally related, feedback being most likely the most important prerequisite of self-amplifying effects. Little causes can thus elicit huge effects.
Model of a hypercycle of the second order. The information carrier I1 instructs two things: first its own replication, and then the production of E1 ....... En. This catalyzes the reproduction of a subsequent information carrier I i + 1. The course of the chain of reactions is directed (according to M. EIGEN and P. SCHUSTER, 1977).
Why does such a system have to reproduce at all? It has already been mentioned that all living systems can be characterized as open systems existing in a far from stable equilibrium dependent on a constant supply of energy. Large molecules and molecular complexes have the tendency to decay and thus to head toward the state of highest possible entropy (2. Law of thermodynamics). Molecules – and thus also molecules carrying information – have thus only a limited life time and a constant new synthesis is necessary to maintain a certain information. Both the rate of production and the rate of decay are not constant but are subject to more or less strong fluctuations. A system has consequently only a chance to survive, if the rate of synthesis is fundamentally higher than the maximal amplitude of decay.
In a hypercycle, a nucleic acid instructs the synthesis of several or many same protein molecules that again participate in the synthesis of new nucleic acid molecules. The amount of newly synthesized material does thus rise exponentially. Viewed strictly theoretically, a hypercycle could be passed through any times, if enough starting material and sufficient energy are supplied.
Since hypercycles describe autocatalytic processes, material and information organized by them can be accumulated. A lack of starting materials like nucleotides or amino acids on one hand, and too small supplies of energy on the other hand leads necessarily to a selection of especially efficient hypercycles, i.e. hypercycles working very fast and with a minimal number of intermediate steps. The feature that we call fitness, i.e. the evolution of features guaranteeing a maximal reproductive success is decisive.
It is difficult to understand, how often hypercycles or beginnings of hypercycles developed during the early stages of the evolution of organisms, finally successful was only one. It has all the features we find in today’s cells, among them replication, transcription, and translation including the genetic code and the ribosomes.
Even though the error rate during the passing on of information is decisively reduced by the aid of proteins, it is not suppressed completely. As a consequence, mutations can accumulate in a hypercycle, too, since the dragging along of erroneous information (the so-called genetic load) has no significant disadvantage as long as the rate of production is higher than that of decay. It can even become advantageous, if an information arises that increases the hypercycle’s fitness and its chance of survival. A hypercycle containing information about the synthesis of proteins able to catalyze the production of required amino acids from their precursors, for example, would be superior. We know now, that amino acids, nucleotides, and other molecules required for the maintenance of cells are the products of syntheses consisting of several steps:
A > B > C > D > E
(with A being the starting product and E the final product)
The intermediate products are only there to be processed further. Their existence is therefore only of advantage, if a further processing is possible. As a consequence, the biosynthetic pathways must have developed backwards starting with the final product during evolution:
- D > E
- C > D > E
- B > C > D > E
- A > B > C > D > E.
The step A > B is for itself without use, because it is E that is required for the hypercycle to function, not B. B becomes only important, because it is finally converted into E.
One more point is important. The accumulation of useful information demands the existence of nearly completely closed reaction compartments, in solution, like for example some kind of inshore water the reaction partners would be lost by diffusion. Each of today’s cells is surrounded by a semi-permeable membrane consisting mainly of lipids and proteins. These complex organization units did certainly not exist right from the beginning. The prototype of a reaction vessel in an abiotic environment could therefore have been fissures (in clay surfaces, for example) or microspheres. Life is a process of constant optimization. The gain of useful information due to mutations and selection of an evolution unit is a long and in effect not too successful way. The combination of units complementary to each other is far more efficient. The characteristic of microspheres to fuse can be regarded as a proof that such fusions did indeed occur.
Certainly, the interactions between reaction units (protocells, spatially isolated hypercycles) were at least as varied as those between today’s cells. The interaction potential increases with the expression and the development of signals at the outer surfaces of the protocells. Their existence causes selectivity and allows to distinguish between same or complementary to each other and foreign.
The order of events is hardly understandable. But the more is known about the structure of proteins, the more plausible seems the reconstruction of the evolution of metabolic pathways. Most simply, the biosynthetic pathways are a linear succession of several reactions catalyzed by proteins (enzymes). Branchings of such chains of reactions are common in the metabolism of today’s cells. A substance X, for example, can alternatively and depending on need either be processed to Y or to Z.
Enzymes consist usually of one or more subunits (polypeptide chains). Proteins consisting of several subunits, i.e. such with a quaternary structure can be regulated. The behaviour of the subunits is co-operative (allosteric). Proteins with quaternary structures exceed in performance those proteins existing of just one polypeptide chain. There is a lot to be said for an increase in performance due to a combination of subunits after the catalytic activities had been perfected. Regulable enzymes occur often at the beginning of a biosynthetic pathway or immediately after a branching leading to the assumption that it may on one hand be advantageous to develop a certain biosynthetic pathway, but that it is moreover better to use it only in case of need.
Many enzymes function with the aid of specific co-enzymes, and it is striking, how many of them are nucleotides or contain nucleotides. It looks therefore as if complexes of proteins and co-enzymes would be remains or parallel developments of interactions between proteins and nucleic acids. During the last years, it became clear that some RNA molecules alone have already catalytic activity. Activities of this type were detected in the excision of introns. In some cases, a RNA molecule is able to link two others together. Base pairings have a decisive part in the recognition of substrates, so that the capacity for evolution is extensively reduced. The catalytic activities of RNA may have had more importance during earlier stages of evolution.
In today’s cells, several thousand different enzyme activities can be detected. It is highly unlikely that all of them developed independently from each other. More probable, certain enzymes developed by alterations of already existing ones. If this is the case, it should be possible to determine the degree of relation among the enzymes as well as the relations between organisms. The results could then be grouped in a phylogenetic tree. The already existing protein-chemical data as well as the determinations of tertiary structures show without doubt that this assumption is indeed true, and that enzymes and other proteins, too, can be grouped into families. The members of these families are similar or even equal in many respects, so that they can be regarded as the products of a diversification of once the same primordial gene.
 Location of the NAD+ binding domain within the polypeptide chains of different dehydrogenases. The different substrate-binding domains have different colours. The nucleotide-binding domain itself consists of two equal sections (light blue and pink) that developed from the same ancestor during evolution. The single dehydrogenases, LDH: lactate dehydrogenase, GAPDH: glycerinaldehydephosphate dehydrogenase, L-ADH: soluble alcohol dehydrogenase, and MDH: malate dehydrogenase differ in their substrate specificity. This again depends on the bond the nucleotide-binding domains have to additional sections at the C- or N-terminus (according to W. EVENTOFF and M. G. ROSSMANN, 1976).
Location of the NAD+ binding domain within the polypeptide chains of different dehydrogenases. The different substrate-binding domains have different colours. The nucleotide-binding domain itself consists of two equal sections (light blue and pink) that developed from the same ancestor during evolution. The single dehydrogenases, LDH: lactate dehydrogenase, GAPDH: glycerinaldehydephosphate dehydrogenase, L-ADH: soluble alcohol dehydrogenase, and MDH: malate dehydrogenase differ in their substrate specificity. This again depends on the bond the nucleotide-binding domains have to additional sections at the C- or N-terminus (according to W. EVENTOFF and M. G. ROSSMANN, 1976).
The globin family harbouring the animal haemoglobins, the myoglobins, and the plant leghaemoglobin provides a concrete example. Leghaemoglobin is just like haemoglobin characterized by the ability to bind oxygen reversibly. It participates in the generation of oxygen-free or oxygen-low compartments in the cells of leguminous roots, so that the nodule bacteria living in these cells in symbiosis with the host plant can fix nitrogen.
The fact that structurally similar or functionally almost alike globins exist both in animal and in plant cells point out that the genes of today’s proteins stem either from a very old primordial gene or that certain coding sequences (exons) are arranged in always new ways so that analogous products develop as soon as an appropriate selection pressure exists.
A further example are the many dehydrogenases (see illustration above) working with NAD as their co-enzyme. The NAD-binding part of the protein (also called apoenzyme in this context) is the same in all dehydrogenases. The single members of this enzyme family differ in their substrate-specificity. The specificity evolved by coupling the NAD-binding part to molecule parts with different substrate-specificities. Coupling means primarily that the nucleotide sequences are combined anew. The results are proteins consisting of several functional domains. In other words, the evolution of proteins was not just restricted to the accumulation of point mutations, but whole information units, parts of genes, were arranged anew.
Since 25 years it is known, that many, if not most eucaryotic and archaebacterial genes consist of parts separated in the genome by non-coding sections. This type of organization of the genetic material seems to have evolved as a consequence of the selection pressure to generate new proteins as fast and especially as less loss-making as possible.
Molecular biological studies performed during the last years gave information about the mechanisms of such recombinations. The principles of practical genetic engineering follow the same principles as many of the recombinations.
The evolution of proteins illustrated here with two examples led to a diversification of the proteins’ performance. It helps at the same time to better understand the evolution of metabolic pathways. We will return to this topic in the next chapter as it shows a way, how to analyze the development of energy-converting mechanisms like photosynthesis and respiration.
Independent of these observations, the structures, amino acid sequences for example, of homologous proteins of different organisms can be compared in order to better understand the degree of relationship between the organisms. This approach is based on the assumption that the evolution of organisms and the evolution of the proteins from which they are made were simultaneous processes. At first, it was assumed that proteins being primary gene products are less subject to selection than other features and that the study of proteins would allow direct statements about the evolution of their genes. Today, we know that proteins, too, are subject to selection pressure. The evolutionary velocity of the proteins, nevertheless, differs considerably from the evolutionary velocity of the organisms from which they were isolated. This is a consequence of the fact that the selection criteria in the environment of organisms differ from those of the environment of proteins. The environment of proteins is the cell content, and its composition is mostly constant. It depends mainly on the properties of the cell’s genome. Therefore, only cells survive, whose proteins fit into the metabolic network. It is consequently not advantageous, if an enzyme with a considerable higher activity develops. It would canalise the substrate supply into a certain direction, i.e. not enough substrate for other metabolic pathways would be there. The whole cell would suffer and be eliminated by selection. Selection does consequently not effect a single gene product, but the total cell genome.
The evolutionary velocity of especially important proteins is extremely low. Histone IV is the classic example. Its amino acid sequence is almost the same in cows and peas. Other, less important genes, like storage proteins are subject to a lesser selection pressure forcing them to remain the same structure, so that differences in the amino acid sequences of closely related species can be detected. An amino acid composition differing from species to species can be found in ribulose-1.5-bisphosphate-caryboxylase, the enzyme catalyzing the first step of carbon dioxide fixation during photosynthesis.
In conclusion, the increasing complexity of cellular functions can be understood by studying the structure and the properties of proteins.
|
|